MPI_Scatterv
Scatters a buffer in parts to all processes in a communicatorint MPI_Scatterv( void *sendbuf, int *sendcnts, int *displs, MPI_Datatype sendtype, void *recvbuf, int recvcnt, MPI_Datatype recvtype, int root, MPI_Comm comm );
Parameters
- sendbuf
- [in] address of send buffer (choice, significant only at root)
- sendcounts
- [in] integer array (of length group size) specifying the number of elements to send to each processor
- displs
- [in] integer array (of length group size). Entry i specifies the displacement (relative to sendbuf from which to take the outgoing data to process i
- sendtype
- [in] data type of send buffer elements (handle)
- recvbuf
- [out] address of receive buffer (choice)
- recvcount
- [in] number of elements in receive buffer (integer)
- recvtype
- [in] data type of receive buffer elements (handle)
- root
- [in] rank of sending process (integer)
- comm
- [in] communicator (handle)
Remarks
MPI_SCATTERV is the inverse operation to MPI_GATHERV.
MPI_SCATTERV extends the functionality of MPI_SCATTER by allowing a varying count of data to be sent to each process, since sendcounts is now an array. It also allows more flexibility as to where the data is taken from on the root, by providing the new argument, displs.
The outcome is as if the root executed n send operations,
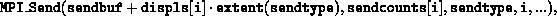
and each process executed a receive,
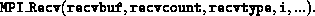
The send buffer is ignored for all non-root processes.
The type signature implied by sendcount[i], sendtype at the root must be equal to the type signature implied by recvcount, recvtype at process i (however, the type maps may be different). This implies that the amount of data sent must be equal to the amount of data received, pairwise between each process and the root. Distinct type maps between sender and receiver are still allowed.
All arguments to the function are significant on process root, while on other processes, only arguments recvbuf, recvcount, recvtype, root, comm are significant. The arguments root and comm must have identical values on all processes.
The specification of counts, types, and displacements should not cause any location on the root to be read more than once.
The "in place" option for intracommunicators is specified by passing MPI_IN_PLACE as the value of recvbuf at the root. In such case, recvcount and recvtype are ignored, and root "sends" no data to itself. The scattered vector is still assumed to contain n segments, where n is the group size; the root-th segment, which root should "send to itself," is not moved.
If comm is an intercommunicator, then the call involves all processes in the intercommunicator, but with one group (group A) defining the root process. All processes in the other group (group B) pass the same value in argument root, which is the rank of the root in group A. The root passes the value MPI_ROOT in root. All other processes in group A pass the value MPI_PROC_NULL in root. Data is scattered from the root to all processes in group B. The receive buffer arguments of the processes in group B must be consistent with the send buffer argument of the root.
Thread and Interrupt Safety
This routine is thread-safe. This means that this routine may be safely used by multiple threads without the need for any user-provided thread locks. However, the routine is not interrupt safe. Typically, this is due to the use of memory allocation routines such as malloc or other non-MPICH runtime routines that are themselves not interrupt-safe.
Notes for Fortran
All MPI routines in Fortran (except for MPI_WTIME and MPI_WTICK) have an additional argument ierr at the end of the argument list. ierr is an integer and has the same meaning as the return value of the routine in C. In Fortran, MPI routines are subroutines, and are invoked with the call statement.All MPI objects (e.g., MPI_Datatype, MPI_Comm) are of type INTEGER in Fortran.
Errors
All MPI routines (except MPI_Wtime and MPI_Wtick) return an error value; C routines as the value of the function and Fortran routines in the last argument. Before the value is returned, the current MPI error handler is called. By default, this error handler aborts the MPI job. The error handler may be changed with MPI_Comm_set_errhandler (for communicators), MPI_File_set_errhandler (for files), and MPI_Win_set_errhandler (for RMA windows). The MPI-1 routine MPI_Errhandler_set may be used but its use is deprecated. The predefined error handler MPI_ERRORS_RETURN may be used to cause error values to be returned. Note that MPI does not guarentee that an MPI program can continue past an error; however, MPI implementations will attempt to continue whenever possible.
- MPI_SUCCESS
- No error; MPI routine completed successfully.
- MPI_ERR_COMM
- Invalid communicator. A common error is to use a null communicator in a call (not even allowed in MPI_Comm_rank).
- MPI_ERR_COUNT
- Invalid count argument. Count arguments must be non-negative; a count of zero is often valid.
- MPI_ERR_TYPE
- Invalid datatype argument. May be an uncommitted MPI_Datatype (see MPI_Type_commit).
- MPI_ERR_BUFFER
- Invalid buffer pointer. Usually a null buffer where one is not valid.
Example Code
The following sample code illustrates MPI_Scatterv.
#include "mpi.h"#include <stdio.h>
#define MAX_PROCESSES 10
int main( int argc, char **argv )
{
int rank, size, i,j;
int table[MAX_PROCESSES][MAX_PROCESSES];
int row[MAX_PROCESSES];
int errors=0;
int participants;
int displs[MAX_PROCESSES];
int send_counts[MAX_PROCESSES];
MPI_Init( &argc, &argv );
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
MPI_Comm_size( MPI_COMM_WORLD, &size );
/* A maximum of MAX_PROCESSES processes can participate */
if ( size > MAX_PROCESSES ) participants = MAX_PROCESSES;
else participants = size;
if ( (rank < participants) ) {
int recv_count = MAX_PROCESSES;
/* If I'm the root (process 0), then fill out the big table and setup send_counts and displs arrays */
if (rank == 0)
for ( i=0; i<participants; i++) {
send_counts[i] = recv_count;
displs[i] = i * MAX_PROCESSES;
for ( j=0; j<MAX_PROCESSES; j++ )
table[i][j] = i+j;
}
/* Scatter the big table to everybody's little table */
MPI_Scatterv(&table[0][0], send_counts, displs, MPI_INT,
&row[0] , recv_count, MPI_INT, 0, MPI_COMM_WORLD);
/* Now see if our row looks right */
for (i=0; i<MAX_PROCESSES; i++)
if ( row[i] != i+rank ) errors++;
}
MPI_Finalize();
return errors;
}
DOWNLOAD
Win32 DeinoMPI.2.0.1.msi
Win64 DeinoMPI.x64.2.0.1.msi